Introduction to Big Data and its Ecosystem
2020-11-15
Data evolution
1 ZB
1,000,000 PB
1,000,000,000,000 GB
1,000,000,000,000,000,000,000 B

Some figures
Some figures in sciences
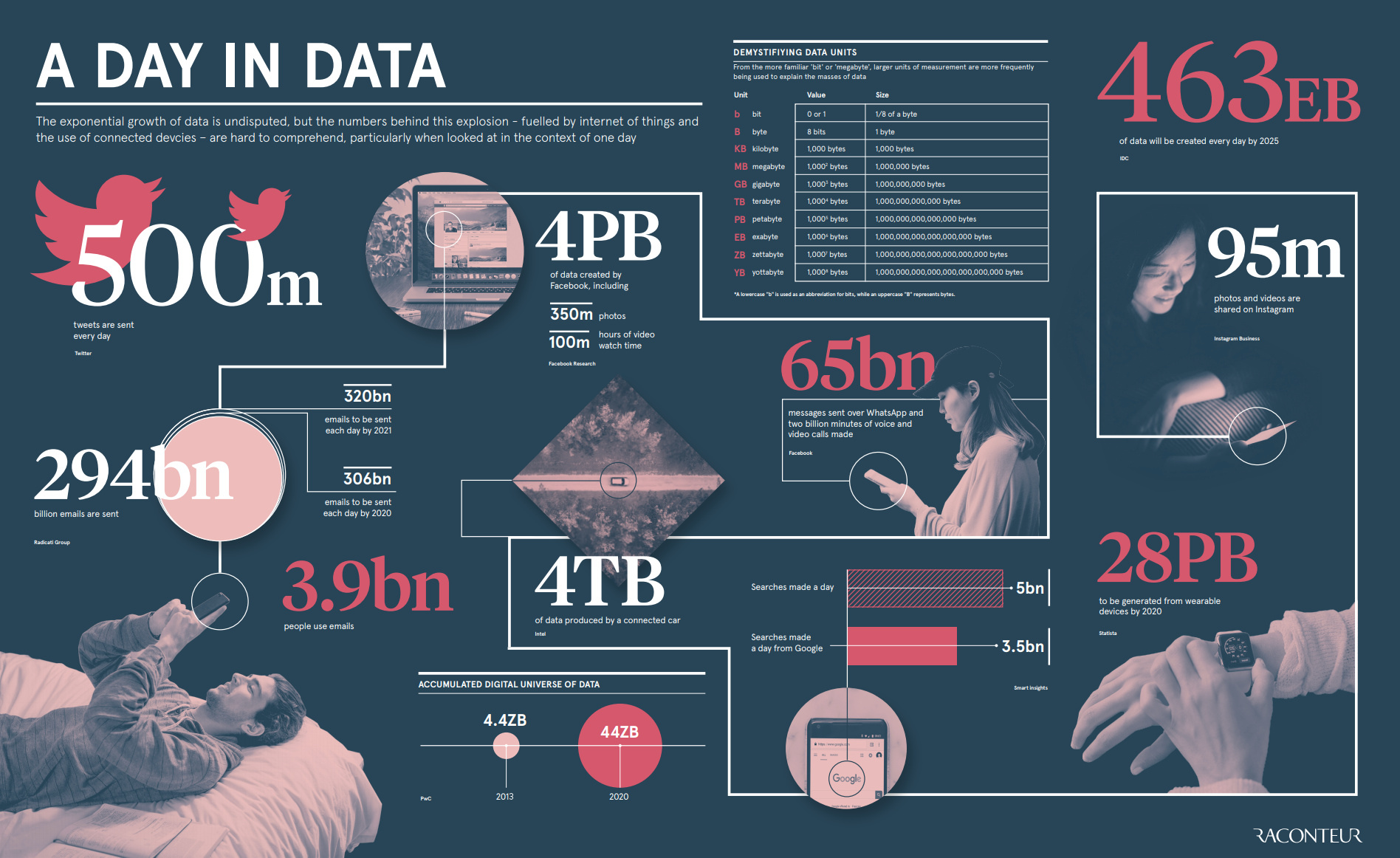
Earth Observation Data
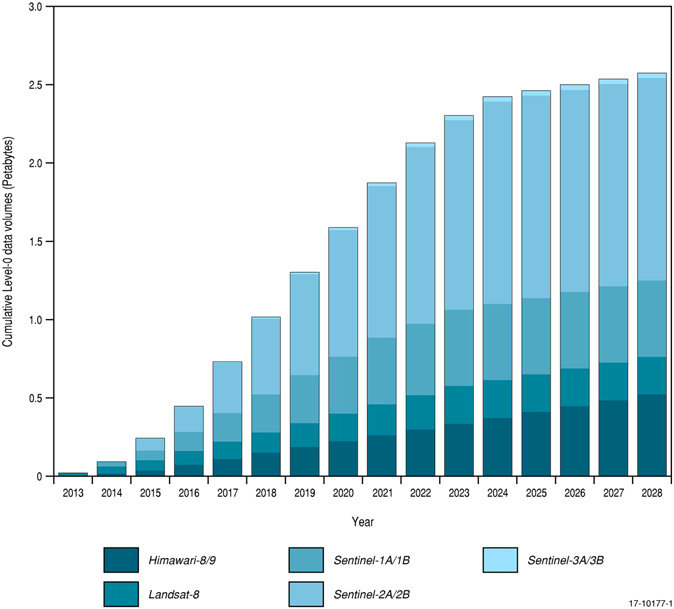
CERN
- The LHC experiments produce about 90 petabytes of data per year
- an additional 25 petabytes of data are produced per year for data from other (non-LHC) experiments at CERN
Quizz
What is the estimated size of the global data sphere?
- Answer A: 175 Petabytes
- Answer B: 175 Exabytes
- Answer C: 175 Zetabytes

Answer link Key: yi
Quizz
Cite some V’s of Big Data (multiple choices):
- Answer A: Validation
- Answer B: Volume
- Answer C: Velocity
- Answer D: Voldemort
- Answer E: Variety

Answer link Key: rf
Hadoop & Map Reduce
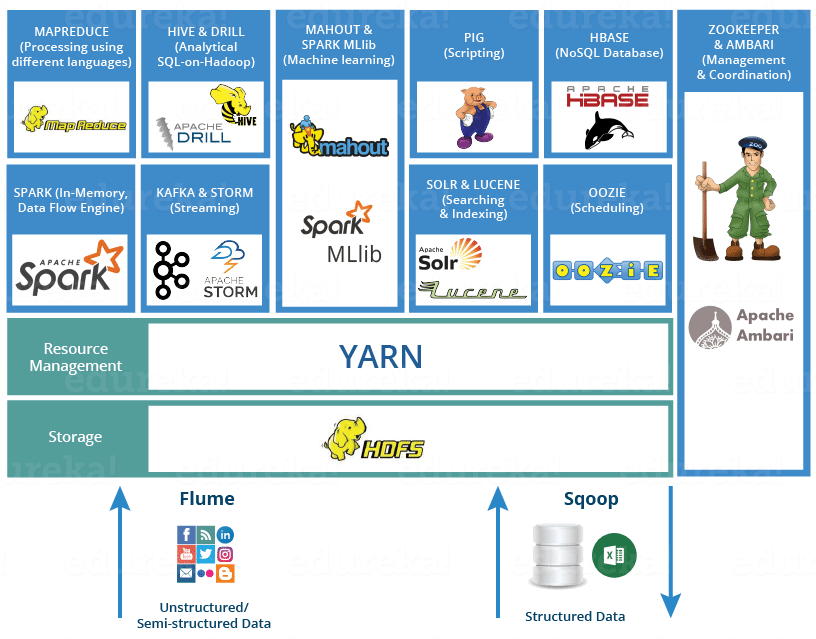
NoSQL (Not only SQL)


Logs, ETL, Time series

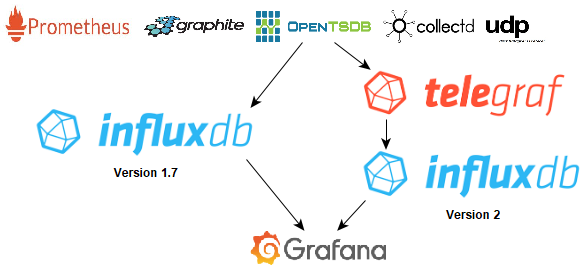
Dataviz
BI (softwares)

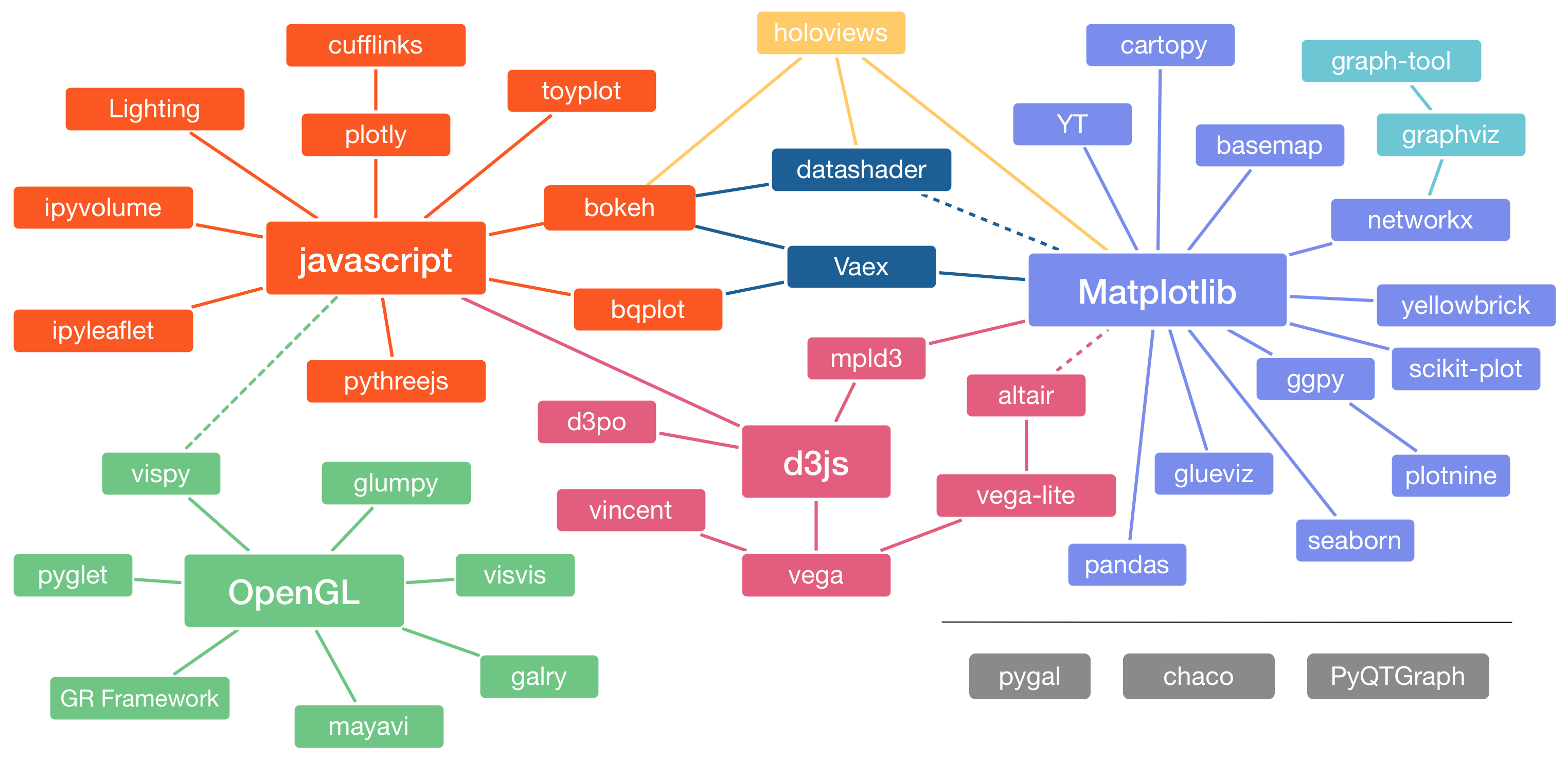
Python (libraries)
Data Science and Machine Learning

Quizz
Which technology is the most representative of the Big Data world?
- Answer A: Spark
- Answer B: Elasticsearch
- Answer C: Hadoop
- Answer D: Tensorflow
- Answer E: MPI (Message Passing Interface)

Answer link Key: dy
Scientific data processing
Data production or scientific exploration:
- Stream processing, or near real time processing from sensor data
- Distributed processing of massive volume of incomming data on computing farm
- Data exploration and analysis
- Data Science
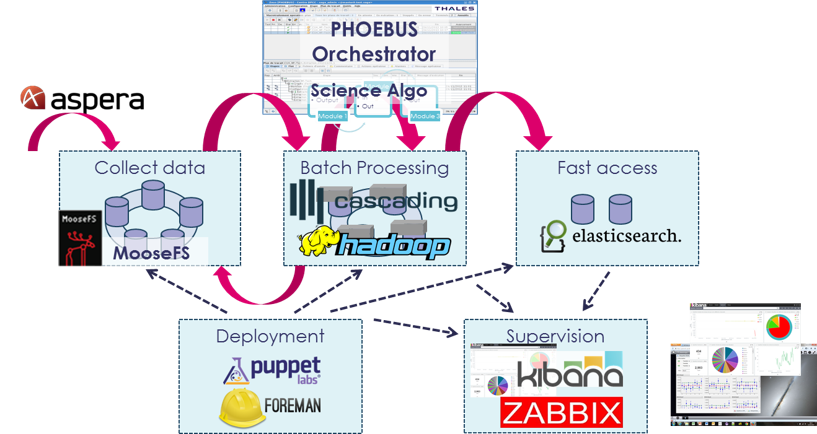
Other main use cases
- Digital twins
- Predictive maintenance
- Smart City
- Real time processing

Quizz
What is the typical volumes of scientific Datasets (multiple choices)?
- Answer A: MBs
- Answer B: GBs
- Answer C: TBs
- Answer D: PBs
- Answer E: EBs

Answer link Key: ri
Distribute datasets and algorithms
- For preprocessing as seen above
- Means to load and learn on large volumes by distributing storage
- Distributed learning with data locality on big datasets
- Distributed hyper parameter search

Quizz
Is Big Data and Machine Learning the same?

Answer link Key: fj