Big Data Platforms, Hadoop and beyond
2020-11-15
A complex ecosystem
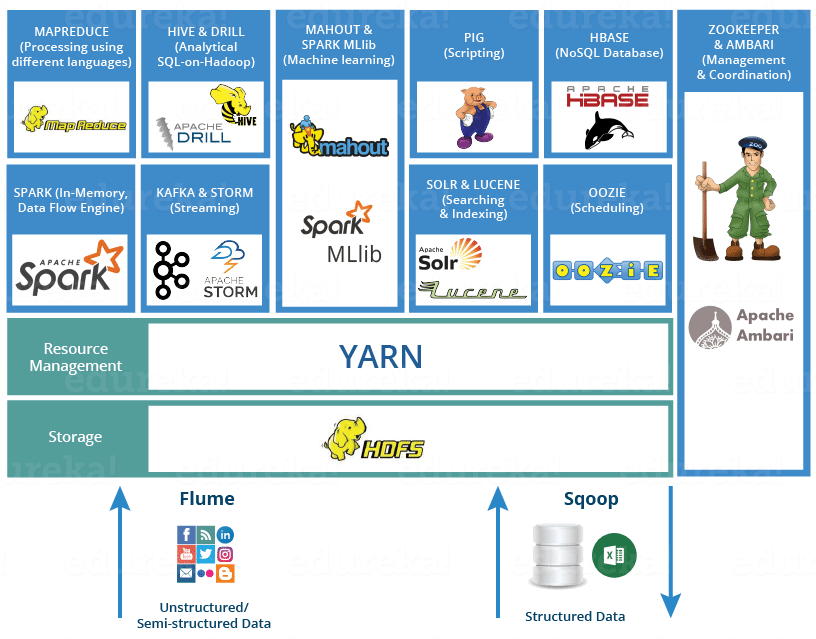
Numerous Apache Software Foundation projects:
- Each covering a specific functionnality
- With their own developer community
- And their own development cycle
Hadoop distributions!
- Cloudera/Horthonworks (2018 fusion)
- MapR
- Others smaller
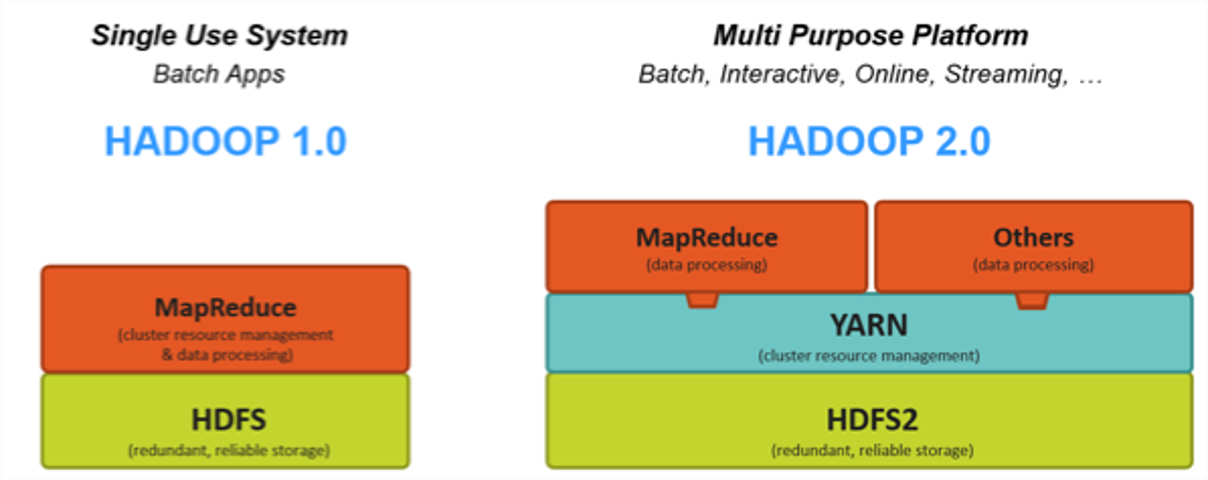
HDFS and MapReduce principles
Two main components of Hadoop
- Distributed Software Defined Storage: HDFS (Hadoop Distributed File
System)
![]()
- Distributed Data Processing: MapReduce
![]()
Principles
- Split and store data on a cluster of servers (with local storage)
- Process data localy (on the server which owns it)
- Horizontal scalability: add or remove machines, on the fly, for compute or storage
- Fault tolerant
Hadoop story, from google to Spark
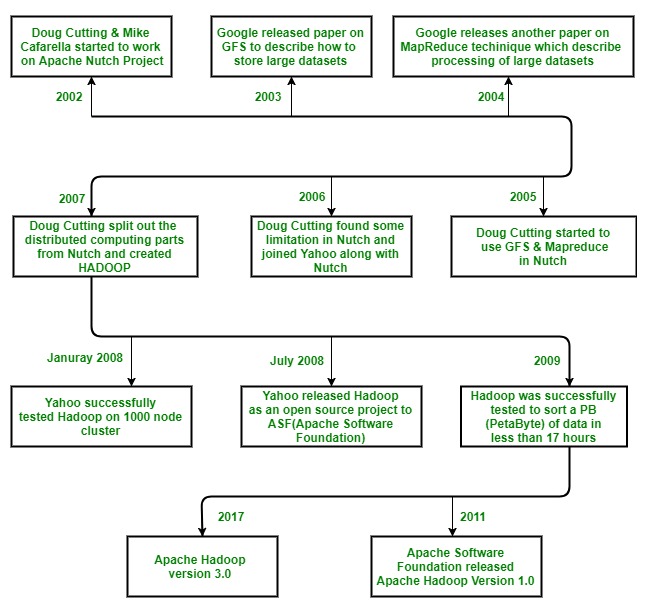
Spark first version in 2014.
Quizz
What are the two building blocks of Hadoop ecosystem (multiple choices)?
- Answer A: Oozie
- Answer B: HDFS
- Answer C: Map Reduce
- Answer D: Servers

Answer link Key: jo
HDFS blocks repartition
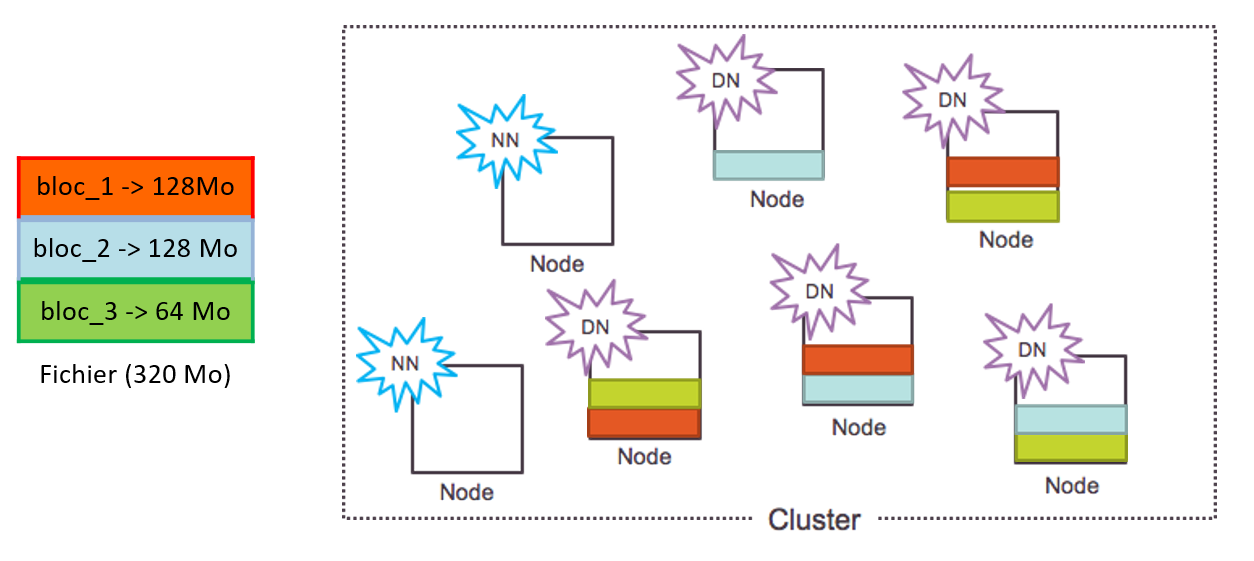
HDFS Architecture

Quizz
What means HDFS?
- Answer A: Hadoop Distributed Functional Services
- Answer B: Hadoop Delayed File System
- Answer C: Hadoop Distributed File System
- Answer D: Hadoop Delayed Functional Services

Answer link Key: me
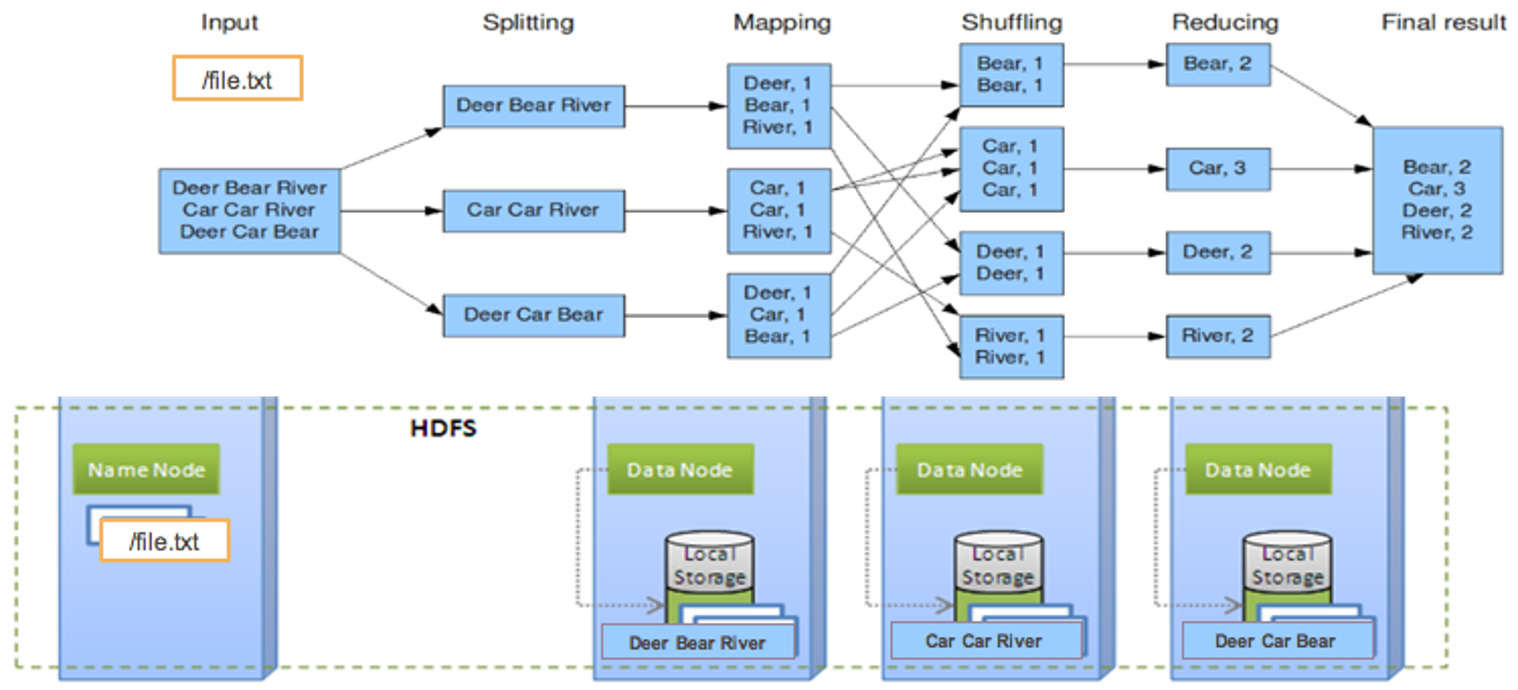
Wordcount (1. storage)
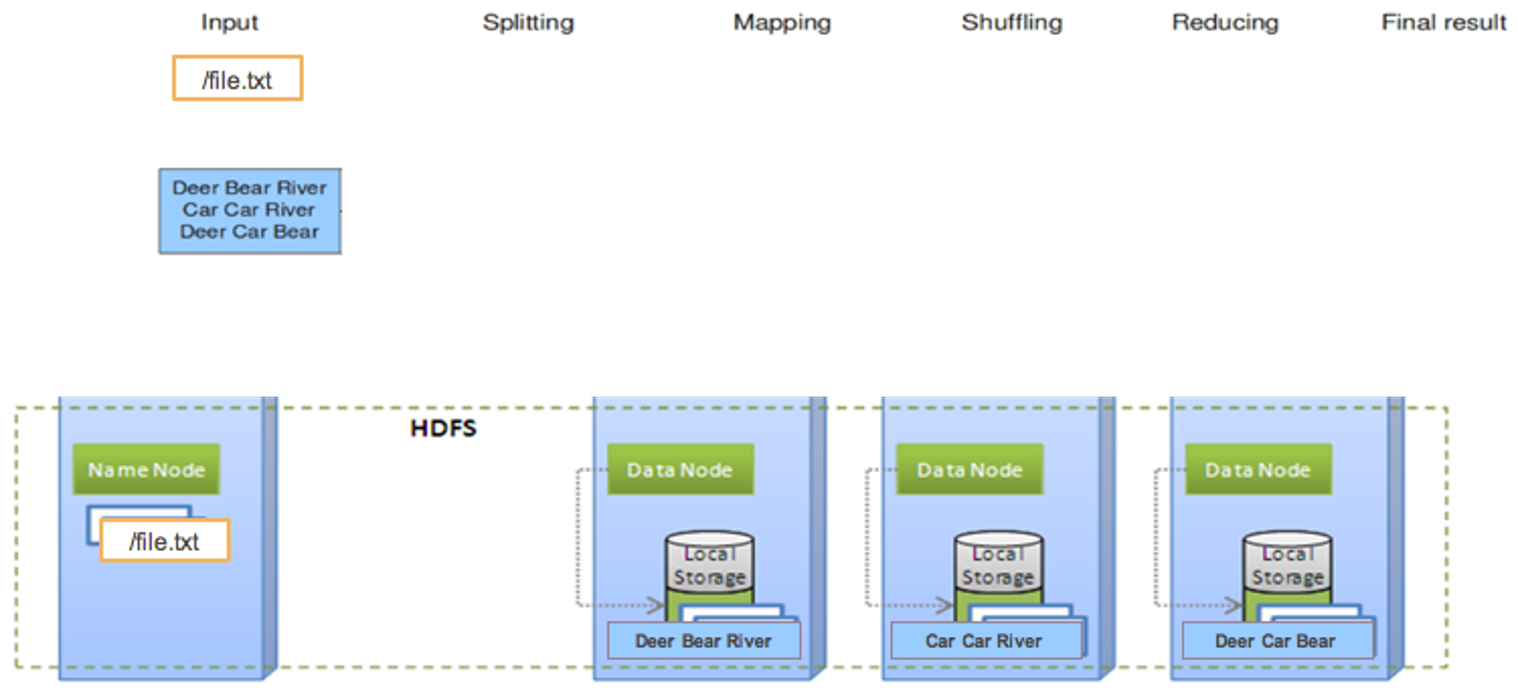
Wordcount (2. split)
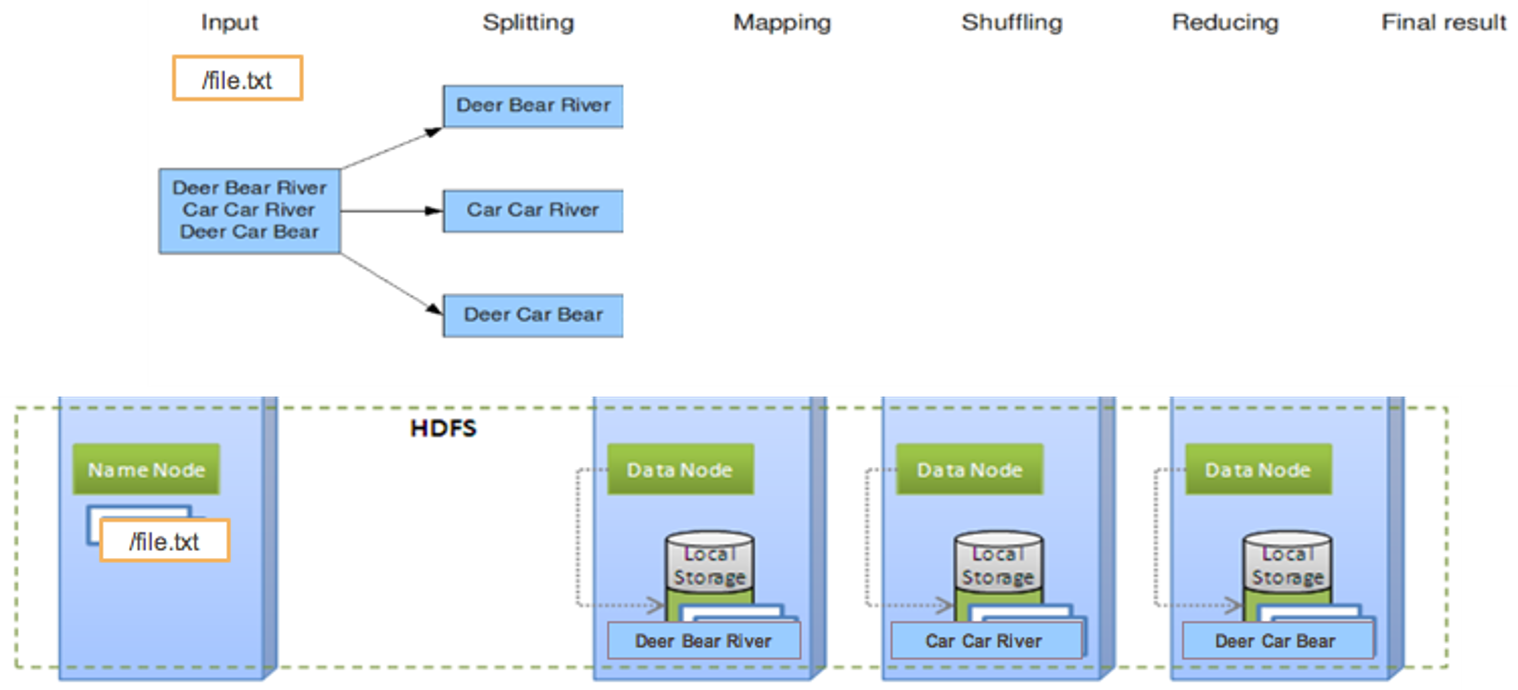
Wordcount (3. map)
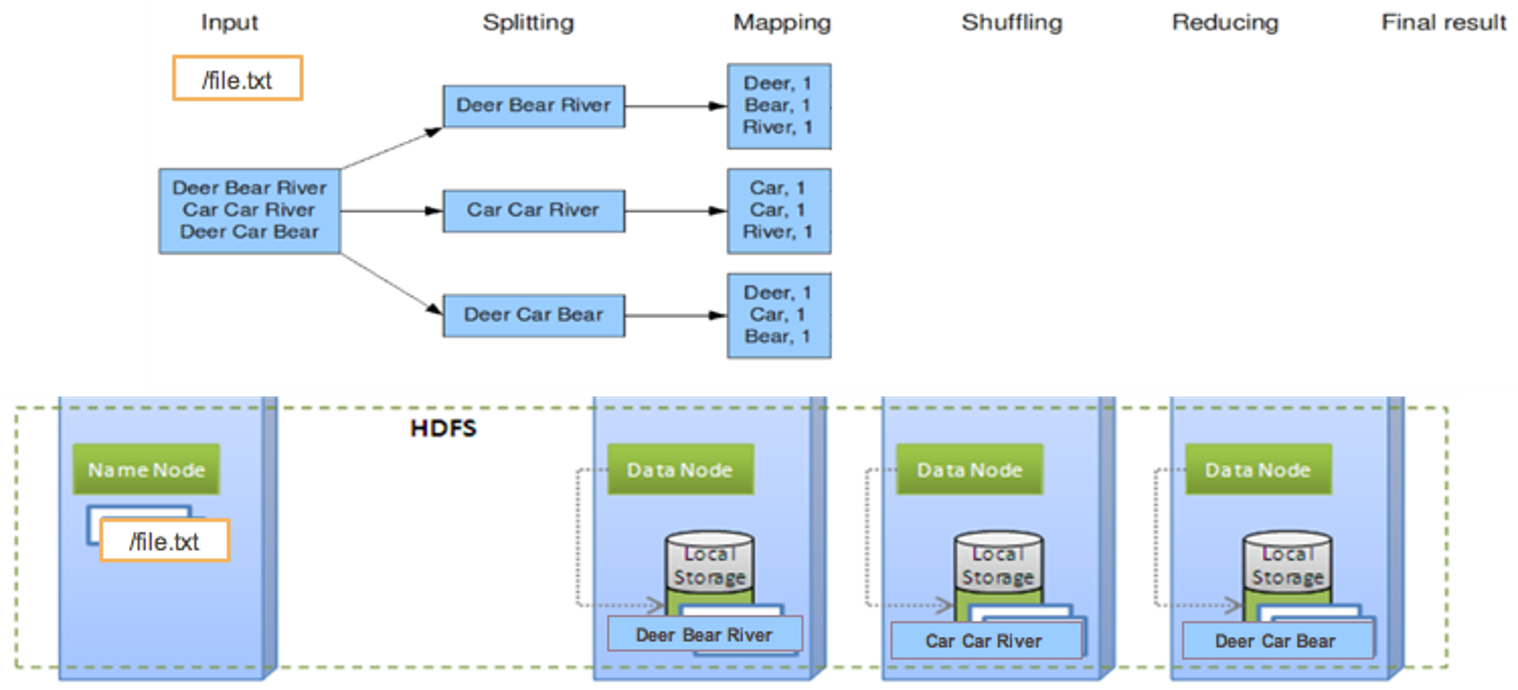
Wordcount (4. shuffle)
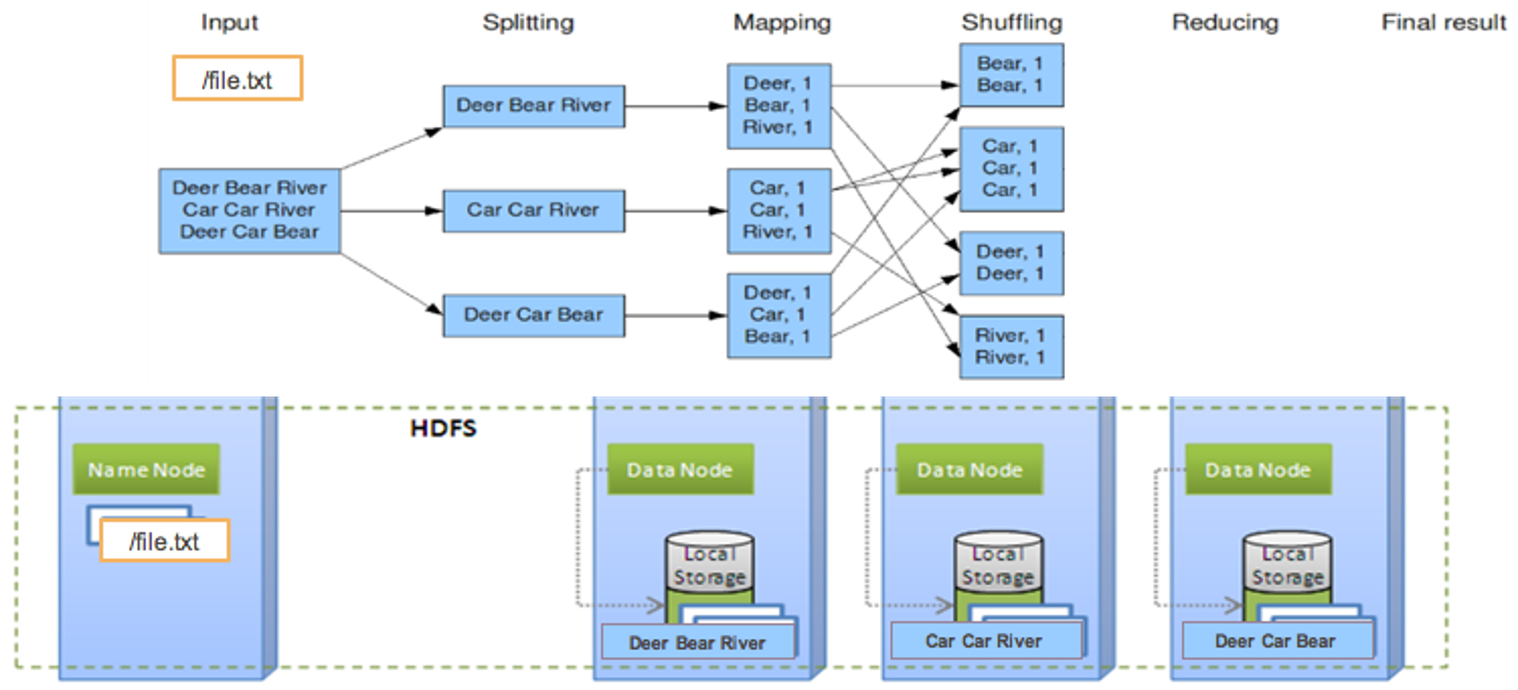
Wordcount (5. reduce)
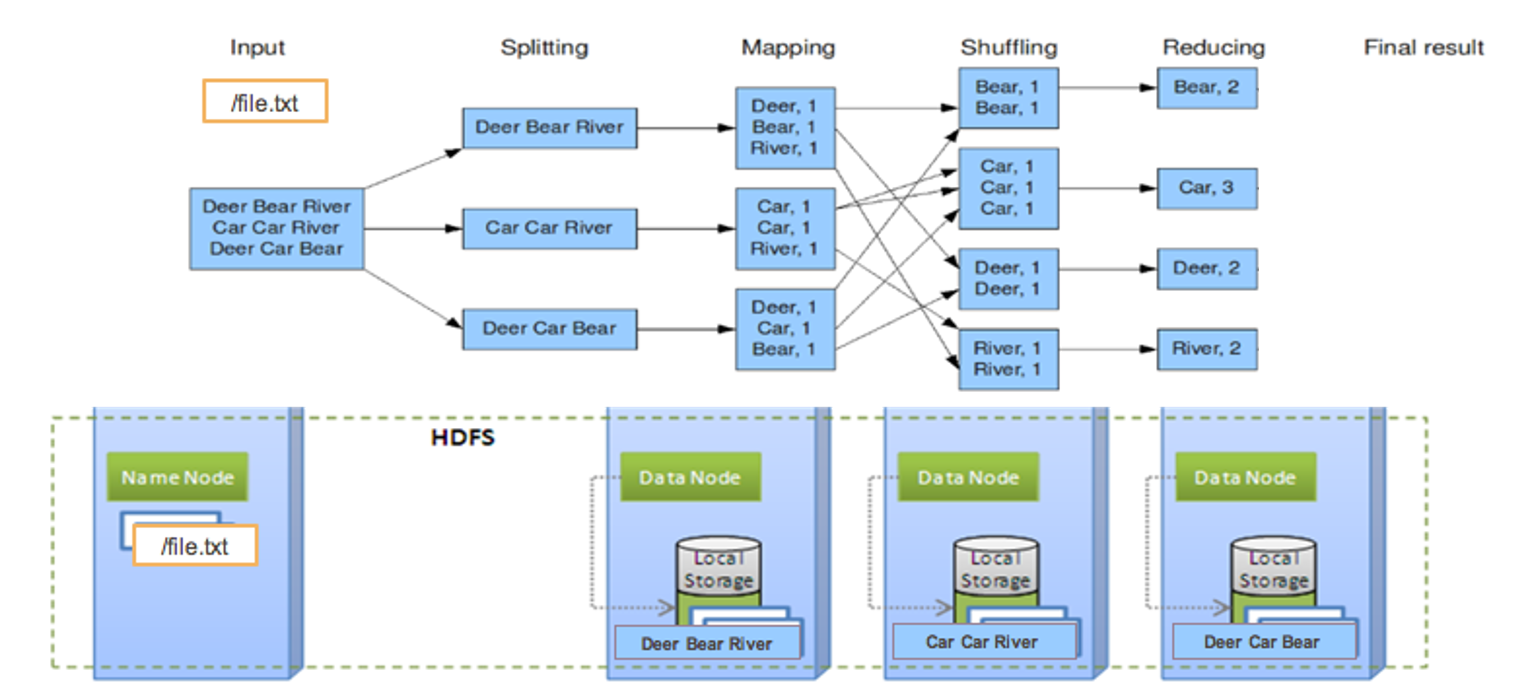
Wordcount (6. result)
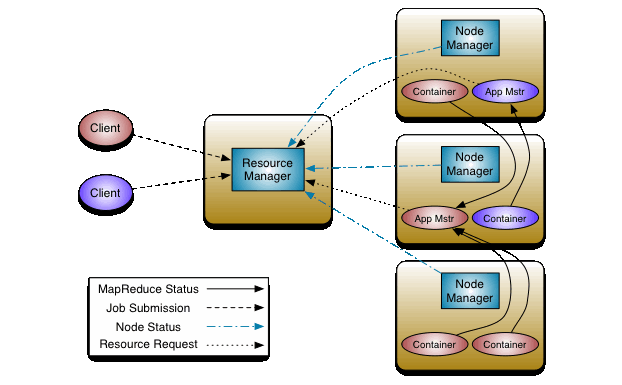
YaRN
- Yet Another Resource Negociator…
- Introduced in Hadoop v2
- Separation between
- Resources scheduling and cluster state
- Job execution and distribution
Quizz
What is the magical hidden step of distributed Map Reduce?
- Answer A: Map
- Answer B: Reduce
- Answer C: Shuffle
- Answer D: Split

Answer link Key: rs
Toward a new data management model
Process centric
- Structured Data
- Internal sources
- Important data only
- Multiple copies
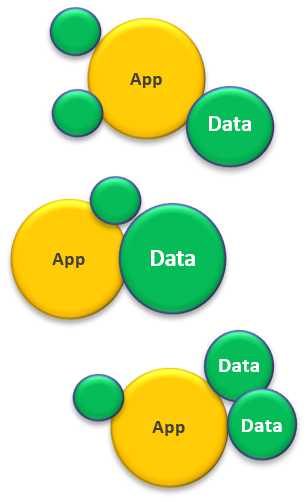
Data centric
- Multiple types (structured, semi-structured, unstructured)
- Multiple sources (internal, external)
- Everything
- One copy
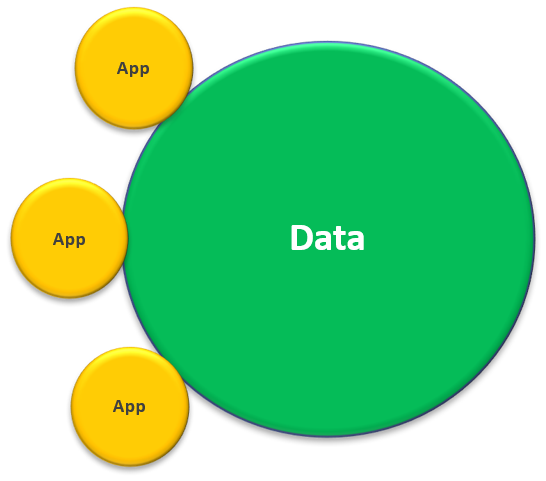
Host and process different kind of data
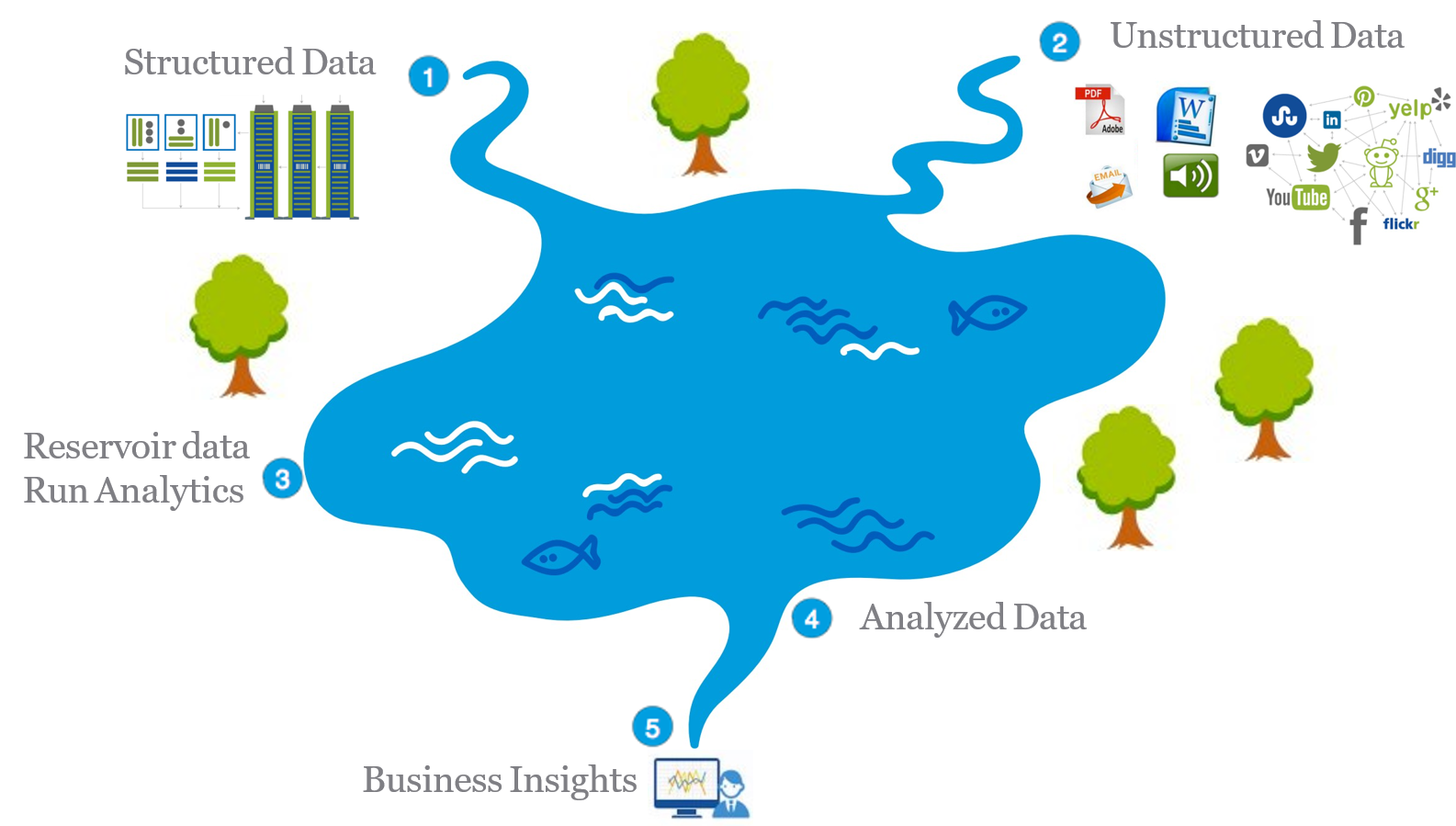
Typical Architecture

CNES Datalake infrastructure example
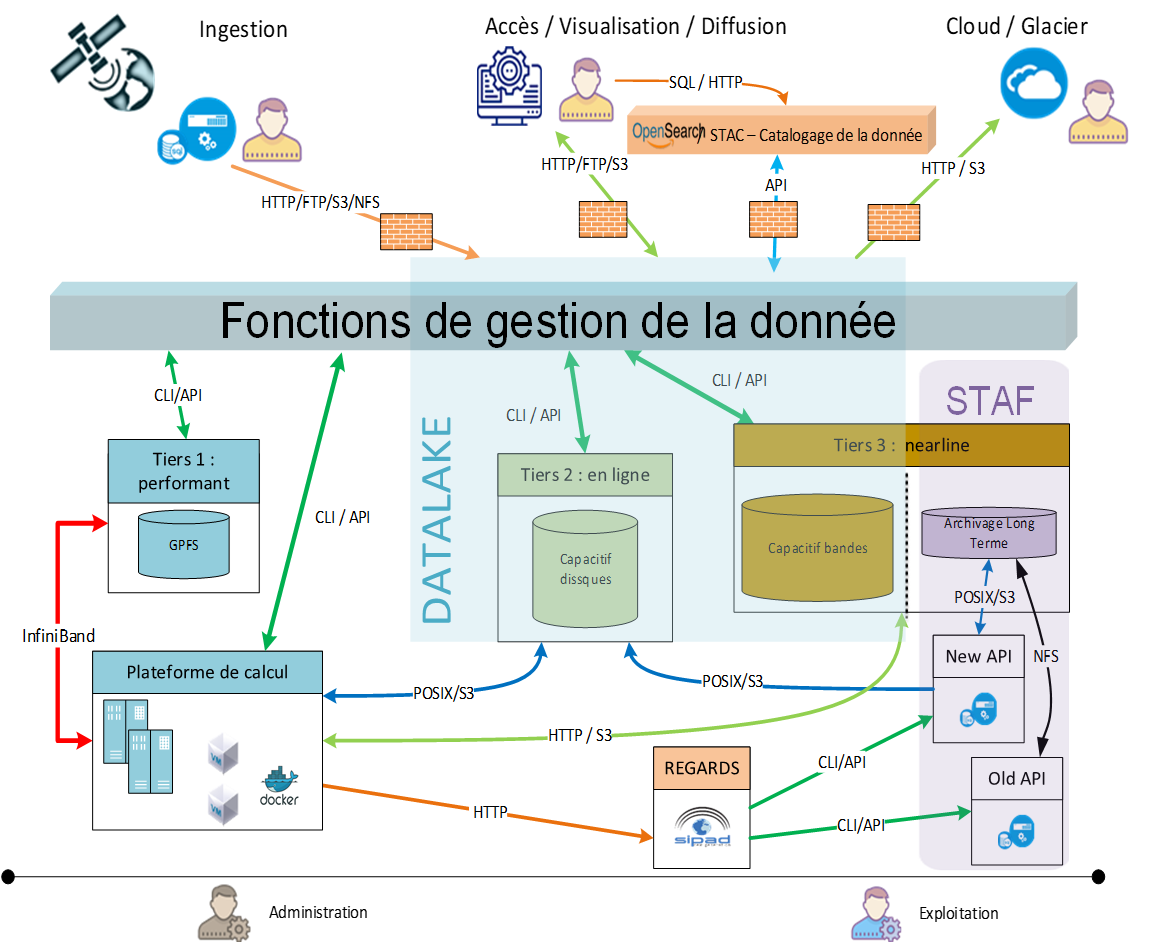
Quizz
What is the goal of a Datalake?
- Answer A: Host structured and filtered Data
- Answer B: Host any kind of Data, at any stages of processing
- Answer C: Standardizing Data structure

Answer link Key: tw
Example in Satellite ground segment
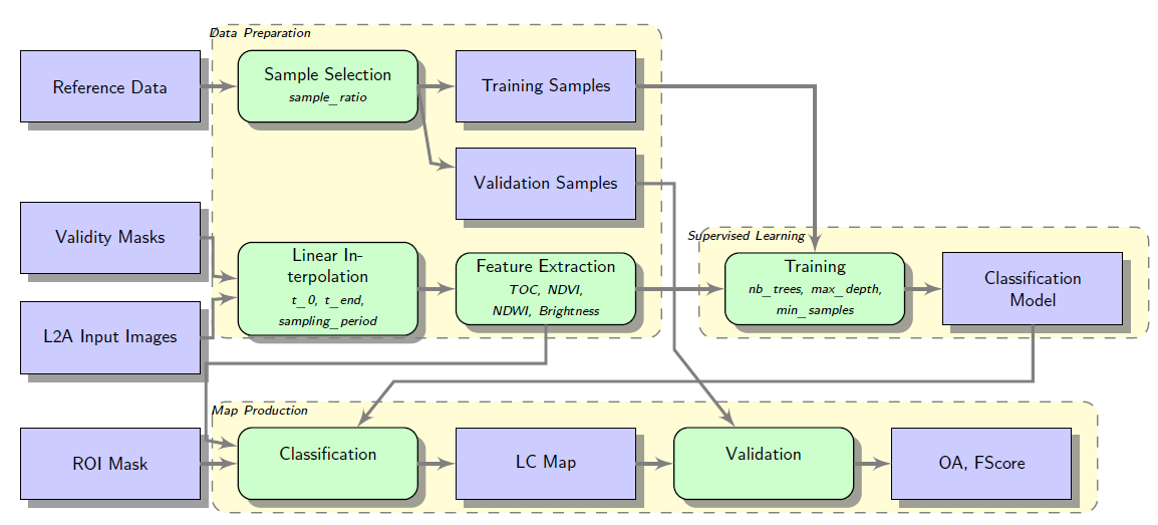
Some tools

Plenty others from Apache or in Python ecosystem.
CNES typical use cases (1)
R&D, Studies, upstream research
- Launchers (combustion, structure)
- Flight dynamics, orbitography
- Sensor data simulation
- Satellite structure and materials
- Technical domain: MPI, HTC, Big Data, AI

CNES typical use cases (2)

Data production and diffusion
- Continuous data production (L0 –> L2)
- Data portals, catalogs
- Processing or reprocessing campains
- Technical Domain: HTC
- CNES Projects: SWOT, THEIA, SWH, SSALTO, PEPS
CNES typical use cases (3)
Data analysis, dowstream research
- Scientific studies on data prodcuts
- Multi temporal or cross domain analysis
- EO or astronomical Data
- Technical Domain: HTC, Big Data, AI
- CNES labs or projects : CESBIO, LEGOS, AI4Geo, EOLab
Architecture, big picture
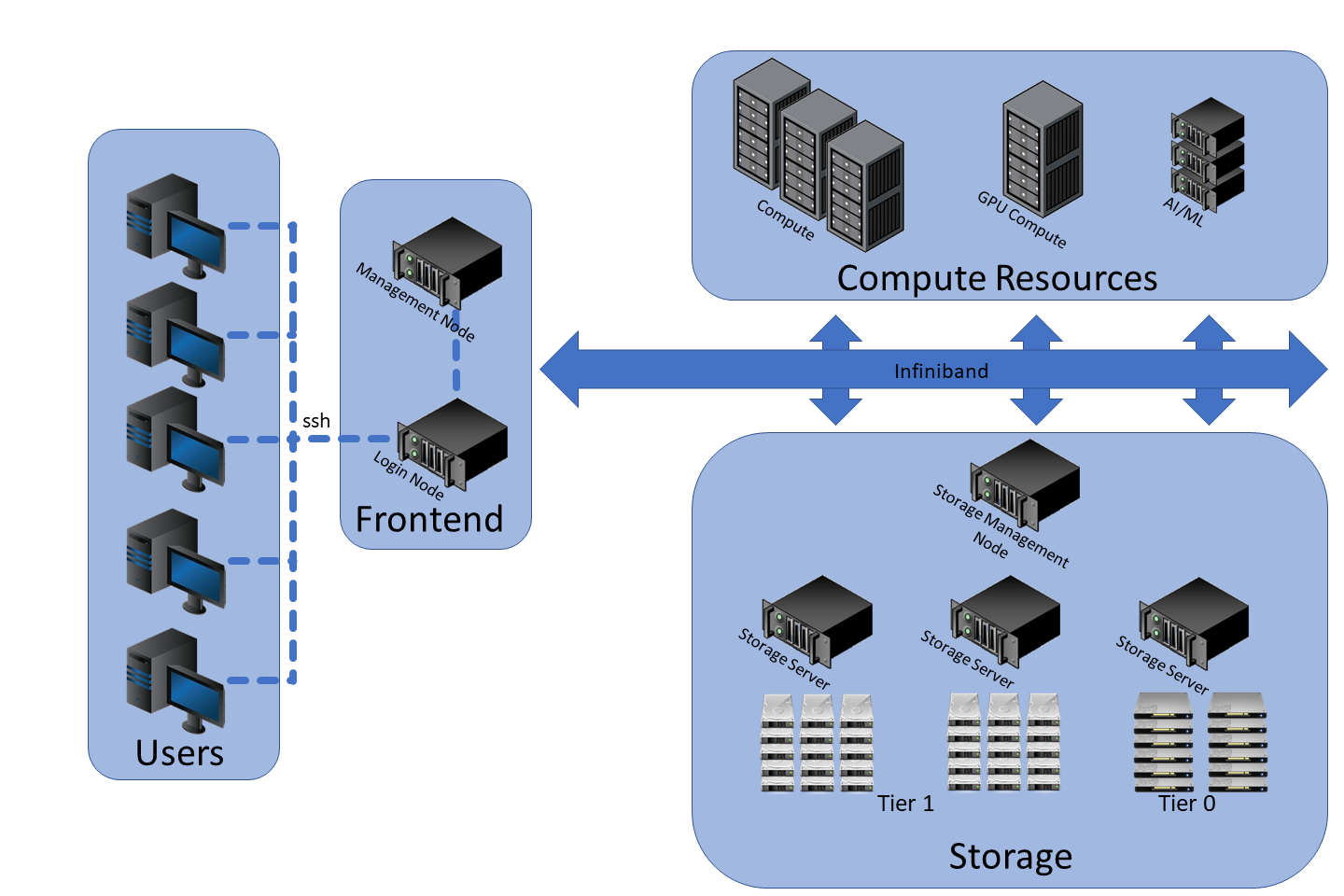
Several things: Login nodes, Admin/Scheduler nodes, Compute resources, Parallel FS, RMDA Network
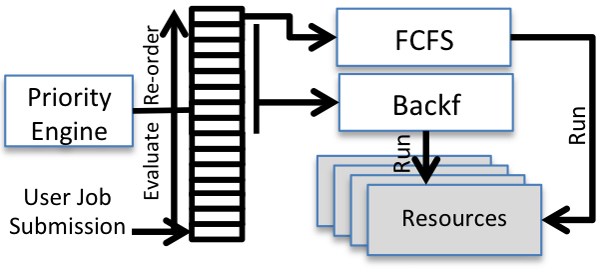
Job scheduler
- Job Queuing System
- Job = Resources, Walltime, Queue, Account, etc.
- Resources management and scheduling
- Priority, fairshare partition, QoS
- SLURM, PBS, SGE, LSF, etc.
#!/bin/bash
#SBATCH --job-name=serial_job_test # Job name
#SBATCH --ntasks=1 # Run on a single CPU
#SBATCH --mem=1gb # Job memory request
#SBATCH --time=00:05:00 # Time limit hrs:min:sec
#SBATCH --output=serial_test_%j.log # Standard output and error log
module load python
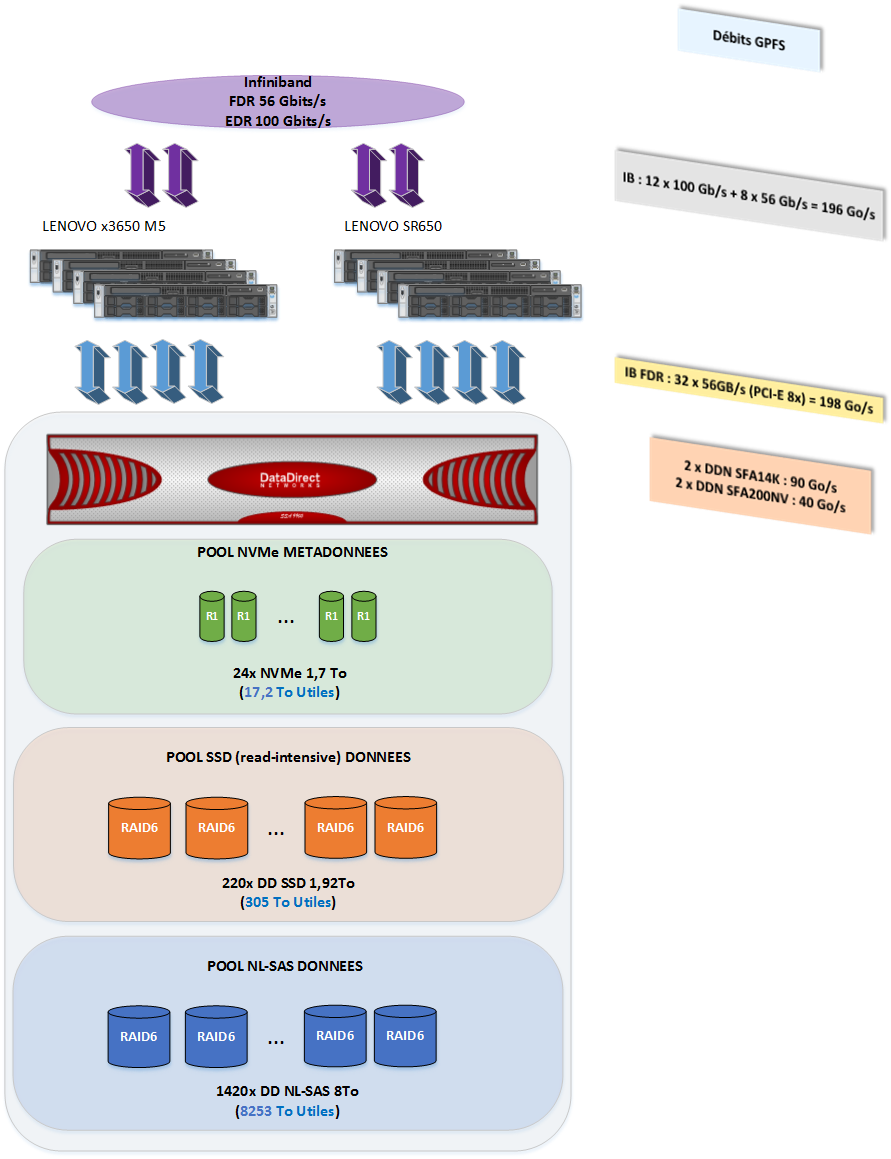
python /data/training/SLURM/plot_template.pyHigh Performance Storage
- POSIX file system
- Usually based on powerfull SAN storage infrastructure
- High performance and capacity: millions IO/s, hundreds GB/s, hundreds PB capacity.
- Spectrum Scale (GPFS) and Lustre
- Other players: WekaIO, BeeGFS
Software technologies
- Classical HPC: C and Fortran
- Compiled languages, hardware optimized
- MPI & OpenMP
- CUDA, OpenACC
- More and More: Python, Julia
- Interpreted Languages, easyer to use
- Lots of performant libraries to reuse (e.g. Numpy, Scipy, Pandas, etc.)
- Parallel and distributed computations:
- Multiprocessing
- MPI4Py : Python over MPI
- Dask, Ray, etc.

HPC platform, story and use case
HPC = High Performance Computing
- Firsts HPC platforms built in the 1960s
- Mainly compute bounds algorithms
- At first for Weather forcasting and Aerodynamic research
- Structure modeling and fluid mecanics by discretization
- Needs (needed?) high performance hardware (network, CPUs, storage)
- Compute and storage are separated
- Uses a resource scheduler

HPDA convergence
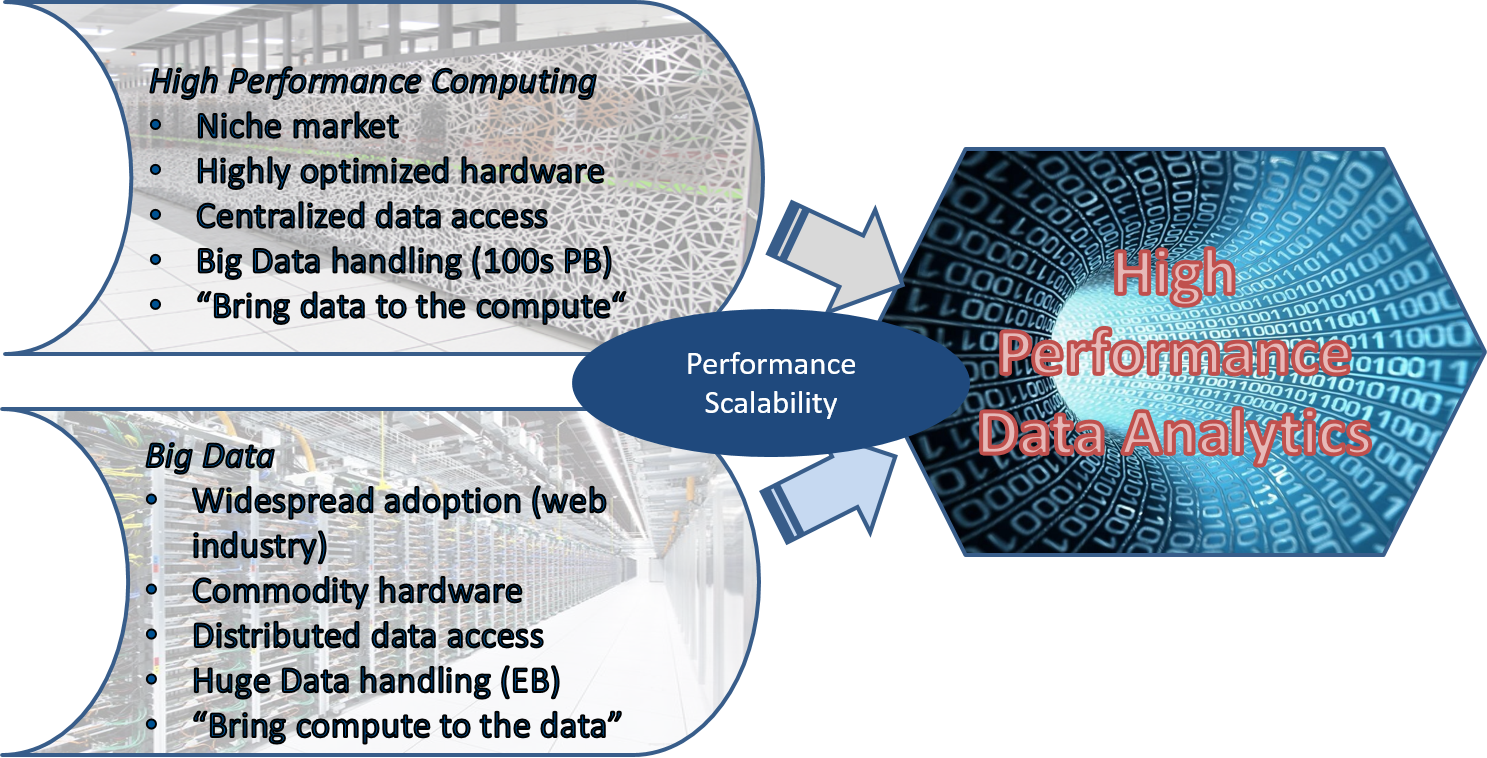
- Hadoop world step towards HPC: YaRN, equivalent to HPC resources scheduler
- HPC step towards Big Data: hardware not so specialized
- Hadoop big limitation: non standard File System and compute and storage colocation
- HPC big limitation: storage can be difficult to scale
Quizz
How Big Data processing differs from classical HPC (multiple choices)?
- Answer A: It is compute bound
- Answer B: It is data bound
- Answer C: It uses specialized hardware
- Answer D: It uses commodity hardware
- Answer E: It is fault tolerant

Answer link Key: xf
Quizz
What technologies are replacing Hadoop ecosystem (multiple choices)?
- Answer A: Map Reduce
- Answer B: MPI (Message Passing Interface)
- Answer C: Spark
- Answer D: Cloud computing and object storage

Answer link Key: ez