Spark Introduction
2020-11-15
Spark vs Map Reduce

- MapReduce alternative which provides in memory processing (100x faster)
- A lot of other things, tools, higher level API
Tools and ecosystem


![]()
![]()
![]()
![]()
Quizz
What’s the main difference between Spark and Hadoop Map Reduce?
- Answer A: Spark uses another algorithm at the heart of its computing model
- Answer B: Spark can work on memory and is much faster
- Answer C: Spark has a better name
- Answer D: Spark provides many more APIs

Answer link Key: hg
APIs
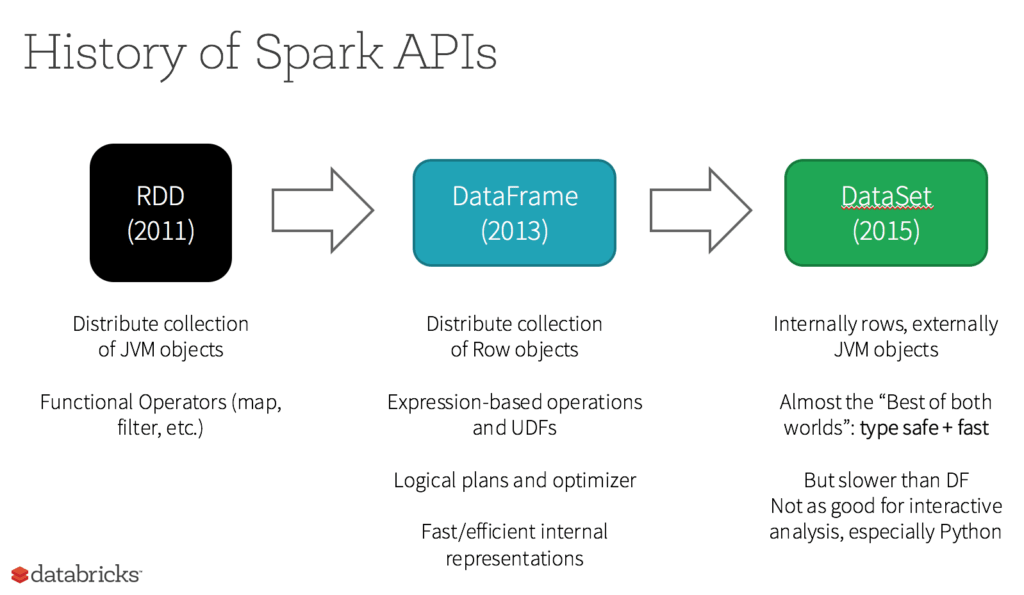
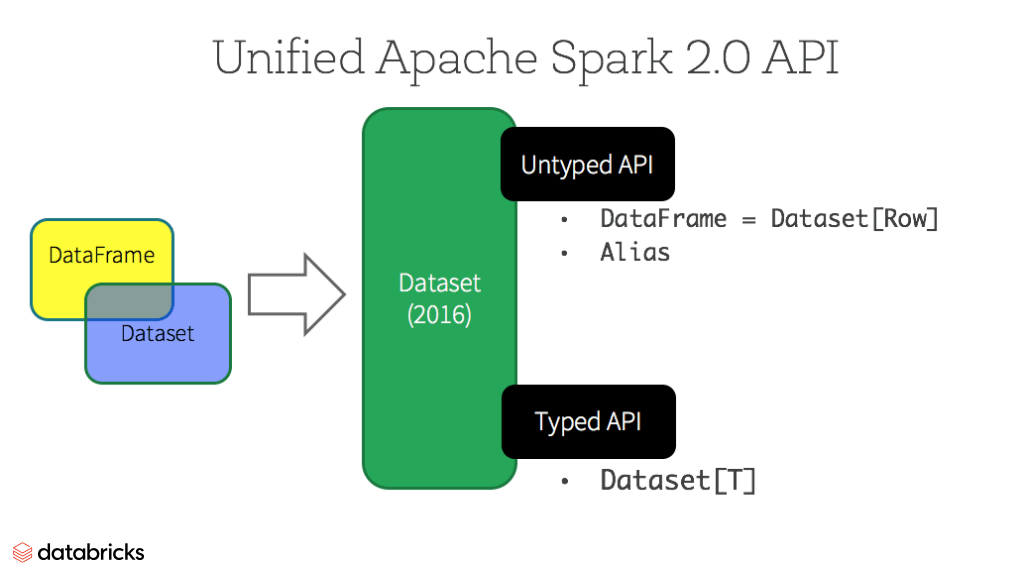
Dataframes and Datasets
- Also an immutable distributed collection of data
- Built on top of RDDs
- Structured data, organized in named columns
- Impose a structure, gives higher-level abstraction
- SQL like operations
- Dataset: strongly typed objects
- Catalyst optimizer, better performances
Execution Plan and DAGS
rdd1.map(splitlines).filter("ERROR")
rdd2.map(splitlines).groupBy(key)
rdd2.join(rdd1, key).take(10)
- Job: each action triggers a job
- Stages:
- Group of Narrow transformation
- Can be processed in one go
- Shuffling (Wide transformations) split stages
- Task: unitary transformation on a data chunk
Streaming


MLLib
- Uses Dataframe API as inputs
- Pipeline made of
- Transformers (analogy to transformation)
- Estimator (can be actions)
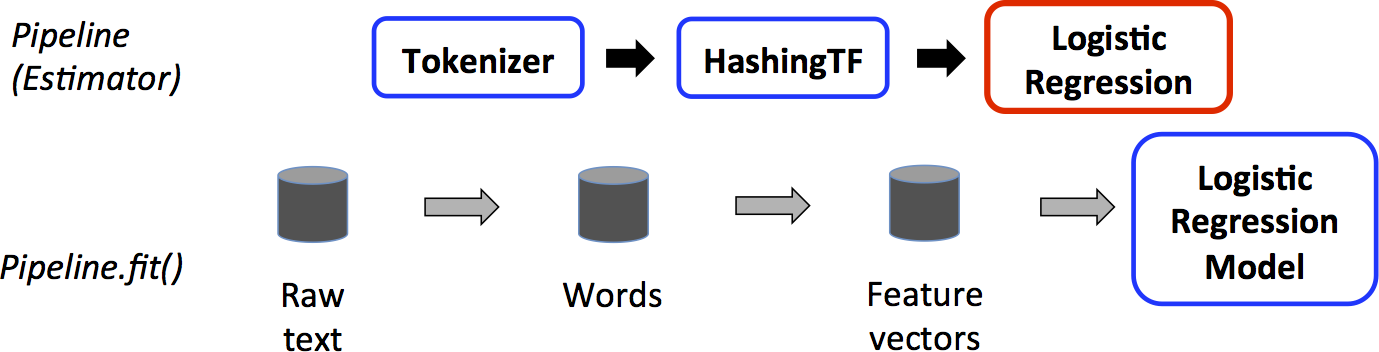
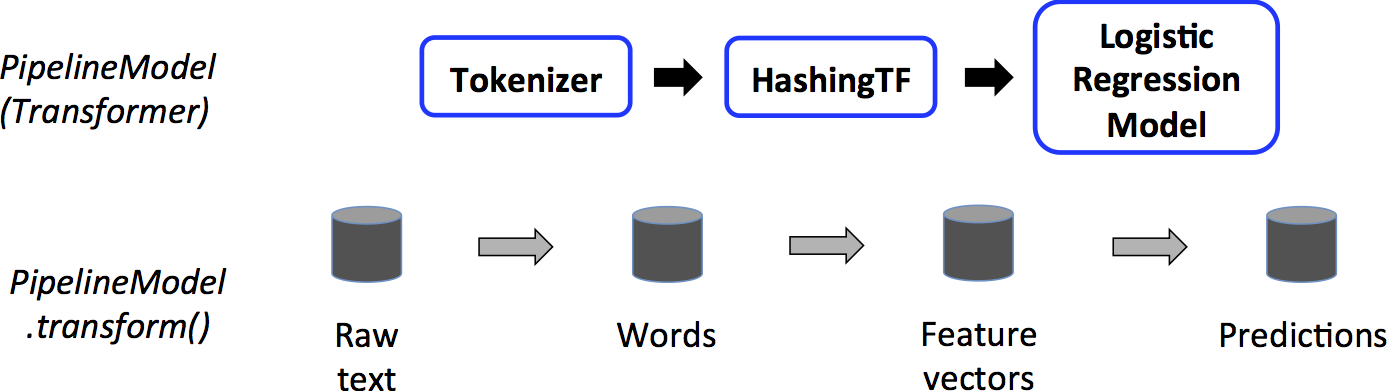
Spark Application and execution

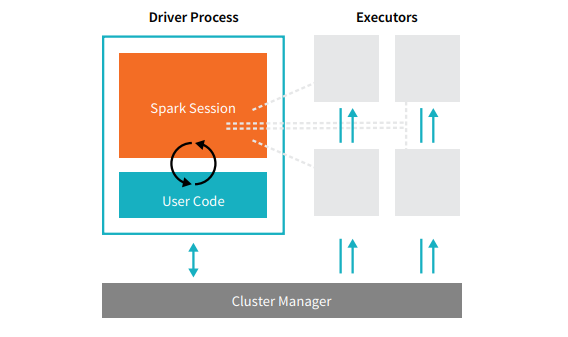
Dashboard
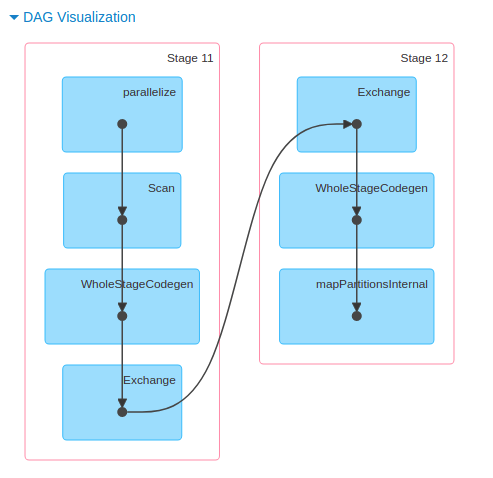
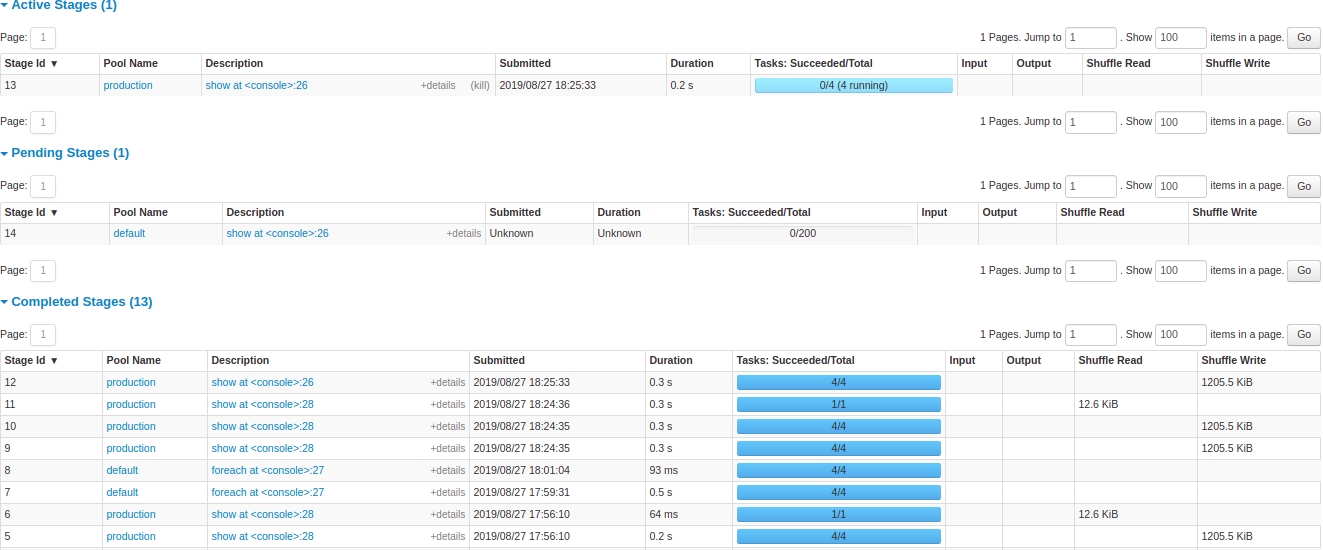
Dashboard 2
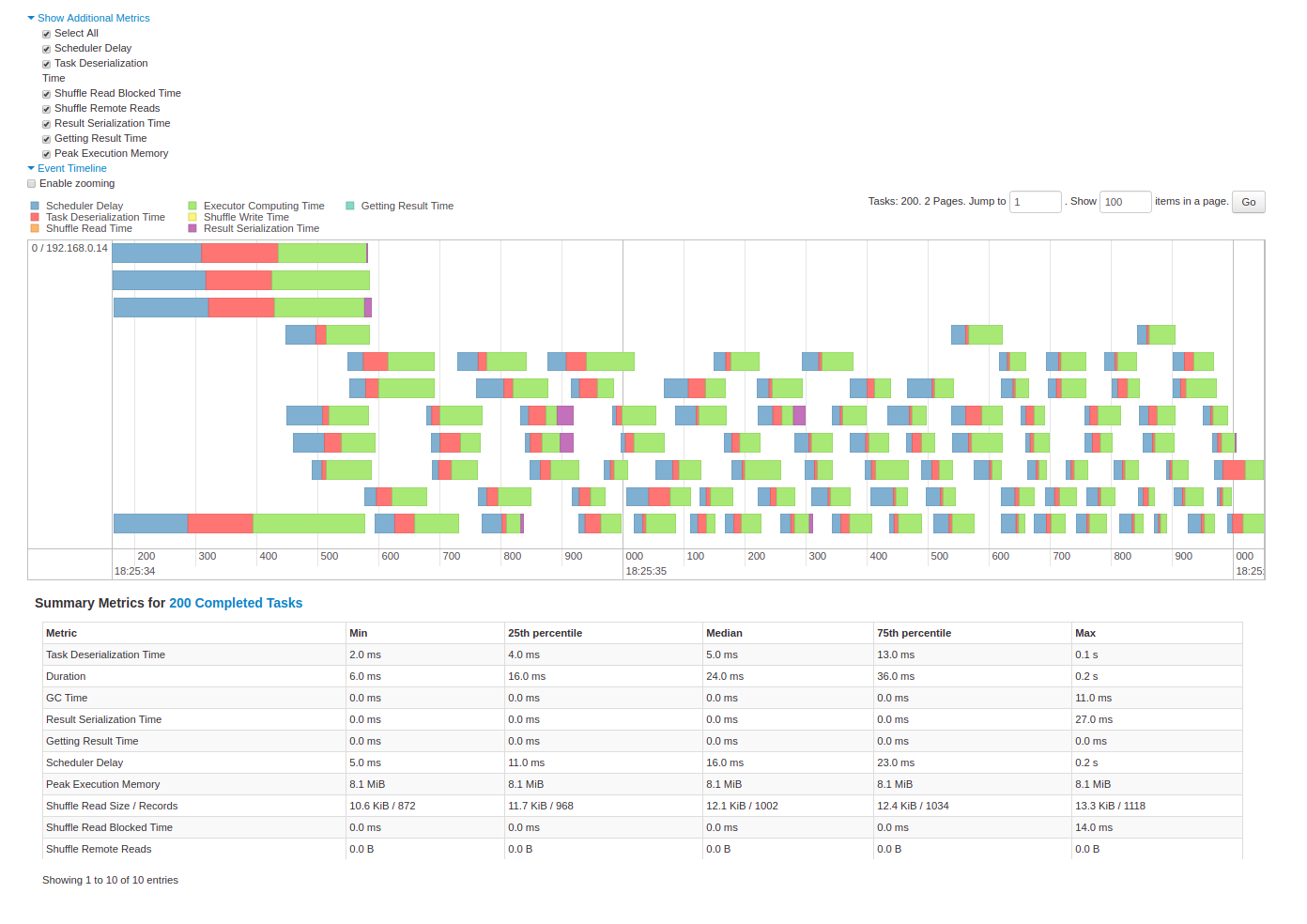
Quizz
What’s the main API of Spark?
- Answer A: MLLib
- Answer B: RDDs (Resilitent Distributed Datasets)
- Answer C: Datasets
- Answer D: Transformations

Answer link Key: op
Context
- Interactive notebook (developed some years ago…)
- Pre-configured
- Warm up on Py computation
- RDDs
- Dataframes